Pytorch学习笔记
科研所迫,开始入坑深度学习。
之前断断续续的学过一些,了解一些概念,但没怎么敲过代码,看源码笔记费劲,更别谈复现了
好友给我推荐了一个通俗易懂的pytorch教程,花了三天看了一遍,这个教程讲得真的很好,为小土堆点赞
今后忘记了再去看一遍视频又十分耗时间,所以在此做一下学习笔记,一是加深印象,二是方便自己后面随时复习

cuda的安装检查
import torch
torch.cuda.is_available()返回Ture,即GPU可用
返回Flase,即GPU不可用,需要去好好检查一下了。
Python两大法宝函数
以torch.cuda.is_available()这个函数为例
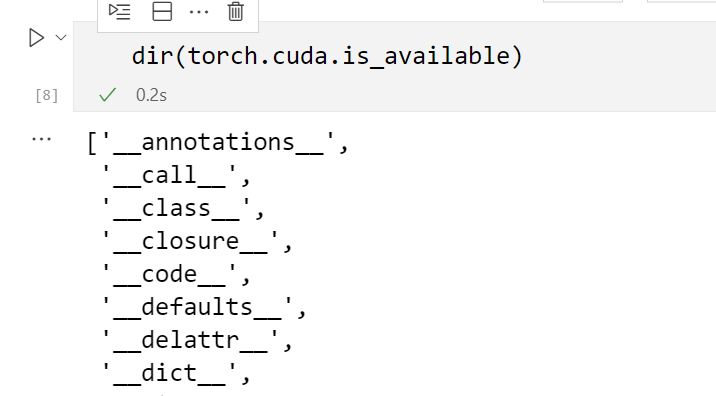
dir(torch.cuda.is_available)以列表的形式返回 torch.cuda.is_available 所有的子函数or方法,具体效果如图所示:
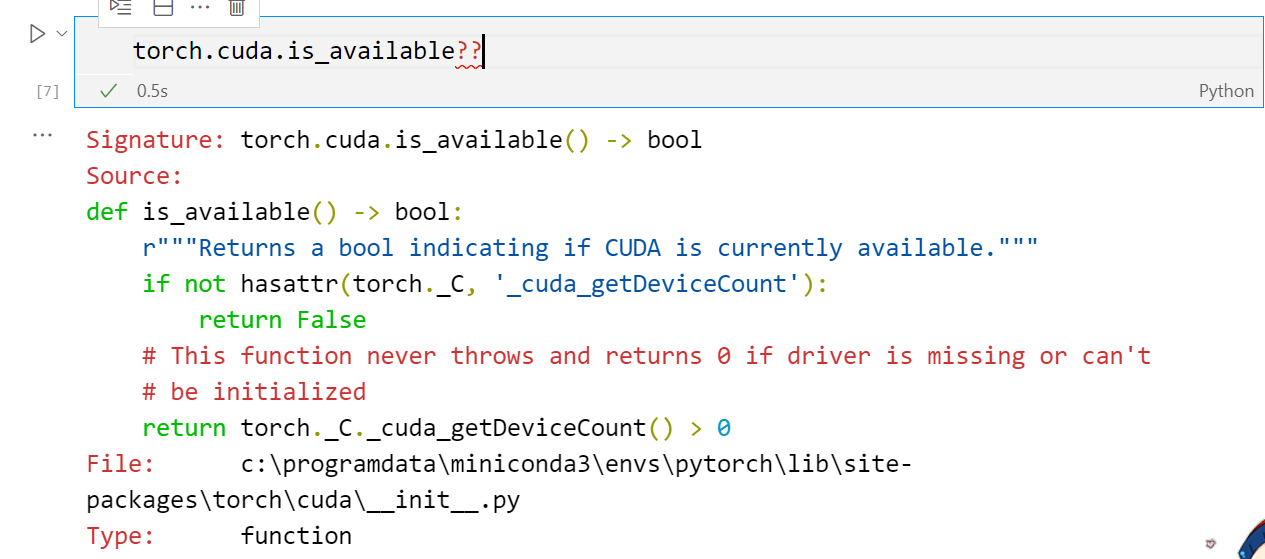
torch.cuda.is_available?? 在函数后加2个?,不要再加括号,即可返回该函数的具体用法,方便用户查看,具体效果如图所示:
Pytorch加载数据
Dataset 定义自己的数据类
torch.utils.data.Dataset 提供一种方式去获取数据及其label,方便用户去定义自己的数据类。在重写dataset抽象类的时候,需要定义__getitem__和__len__这个两个函数
import torch
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
# 后面的变量都需要一开始在这初始化
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
# __getitem__ 是必须要的重写函数,不要写错了
def __getitem__(self,index):
img_name = self.img_path[index]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
# 返回的是一个数组
return img,label
def __len__(self):
return len(self.img_path)
# r表示不转义(python基础)
root_dir = r"hymenoptera_data\train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)
# 返回的是一个数组,所以a = img ,b = label (python基础)
a,b = bees_dataset[1]
a
dataloader如何处理数据集中的数据
torch.utils.data.dataloader 官方文档解释为:
Combines a dataset and a sampler, and provides an iterable over the given dataset.
简而言之:在后面的步骤中,如何去处理数据集中的数据,常用的参数有
dataset:需要加载的是数据集是哪个 dataset from which to load the data.
batch_size:一次要加载多少个数据 how many samples per batch to load,default:
1shuffle:每轮加载是否打乱顺序,set to
Trueto have the data reshuffled at every epoch (default:False).
import torch
from torch.utils.data import DataLoader
#加载内置的数据集
test_set = torchvision.datasets.CIFAR10(root = './CIFAR10',train = False,transform = trans_tensor ,download=False)
#在后面的步骤中如何去处理数据集的数据呢,每次去64个,每轮采用中不打乱
test_loader = DataLoader(dataset = test_set, batch_size = 64, shuffle = True)
for data in test_loader:
# 一个data里有64个img,64个targets
imgs,targets = data
print(imgs.shape)
print(targets)
可以看到,imgs.shape = [64, 3, 32, 32] ,64张照片,3个通道,32*32像素
targets是一个64个数字的列表
由此验证,一个data里有64个img,64个targets。
TensorBoard的使用
what is TensorBoard
对大部分人而言,深度神经网络就像一个黑盒子,其内部的组织、结构、以及其训练过程很难理清楚,这给深度神经网络原理的理解和工程化带来了很大的挑战。
TensorBoard是tensorflow内置的一个可视化工具,现在在pytorch也可以使用,具体可以做:
- 跟踪和可视化损失及准确率等指标
- 可视化模型图(操作和层)
- 查看权重、偏差或其他张量随时间变化的直方图
- 将嵌入投射到较低的维度空间
- 显示图片、文字和音频数据
- ……
how to use TensorBoard in pytorch
直接在代码里记录吧
import torch
import numpy as np
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
# 给本次的可视化结果命个名,运行代码之后会发现多一个logs文件夹
writer = SummaryWriter("logs")
for i in range(100):
# 在可视化结果添加一个表格,表格名字为"y=2x",纵坐标为2*i,横坐标为i
writer.add_scalar("y=2x",2*i,i)
image_path = r"hymenoptera_data\train\ants\0013035.jpg"
image = Image.open(image_path)
image_array = np.array(image)
# 在可视化结果添加一张照片,表格名字为"y=2x",纵坐标为img_tensor ,横坐标为step第几步骤了
# If you have non-default dimension setting, set the dataformats argument.
writer.add_image("TEST",img_tensor = image_array,global_step = 1,dataformats=("HW3"))
writer.close()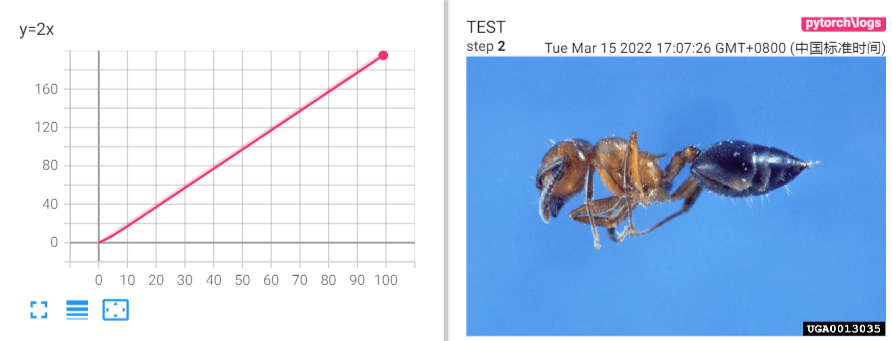
我对TensorBoard的理解是一个嵌入式的强大Excel,方便我们对于训练过程的理解
transform的使用
torchvision.transforms是pytorch中的图像预处理包,包含了很多种对图像数据进行变换的函数
就是将图像数据的格式做各种转化,满足后续的使用
下面写一下常用的变换方法
import torch
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# 加载一张照片进来做测试
image_path = r"hymenoptera_data\train\ants\892108839_f1aad4ca46.jpg"
image = Image.open(image_path)
# ToTensor
# Convert a PIL Image or numpy.ndarray to tensor.
trans_tensor = transforms.ToTensor()
img_tensor = trans_tensor(image)
writer.add_image("ToTensor",img_tensor)
# Normalize逐channel的对图像进行标准化(均值变为0,标准差变为1),可以加快模型的收敛
trans_norm = transforms.Normalize([3,4,80],[3,4,5])
img_norm = trans_norm(img_tensor)
writer.add_image("Normalize",img_norm,3)
# Resize
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img_tensor)
writer.add_image("Resize",img_resize,4)
# Compose 把多个transforms的功能按照列表集合到一起
trans_resize_2 = transforms.Resize((1026,512))
trans_compose = transforms.Compose([trans_resize_2,trans_tensor])
img_resize_2 = trans_compose(image)
writer.add_image("Compose",img_resize_2,2)
# RandomCrop 随机裁剪,不按照比例进行缩放
trans_RandomCrop = transforms.RandomCrop((300))
trans_compose_2 = transforms.Compose([trans_RandomCrop,trans_tensor])
for i in range(10):
img_crop = trans_compose_2(image)
writer.add_image("RandomCrop",img_crop,i)
writer.close()数据集的使用
pytorch提供了很多自带的开源数据集,我们只需要通过很简单的几行代码即可调用
方便初期的学习使用,后期就需要构建自己的数据集
影像数据集地址:https://pytorch.org/vision/stable/datasets.html
CIFAR10论文地址:https://www.cs.toronto.edu/~kriz/cifar.html
这里我们以CIFAR10为例
import torch
import torchvision
from torch.utils.data import DataLoader
# 把我们加载进来的图片转变成tensor格式,方便后续处理
trans_tensor = torchvision.transforms.ToTensor()
train_set = torchvision.datasets.CIFAR10(root = './CIFAR10',train = True,transform = trans_tensor ,download=False)
test_set = torchvision.datasets.CIFAR10(root = './CIFAR10',train = False,transform = trans_tensor ,download=False)不同数据集参数的调用上会有一些差别,基本大同小异,这里以CIFAR10为例;
root:数据集路径在哪
train:这是数据集中的训练集吗
transform:需要对数据集中的数据做哪些预处理吗,我这里的ToTensor就是变换张量处理
download:是否需要从网络上下载该数据集,如果下载过慢可以自己去相应的下载地址里用IDM等工具主动下载神经网络的搭建
可以把以下代码当成个模板,有什么内容在里面填充即可
以下只涉及了前向反馈,是最简单的模板
import torch
from torch import nn
# nn.Module:Base class for all neural network modules.
# 所有的模型都必须继承这个类
class Module(nn.Module):
def __init__(self):
super().__init__()
# 所有的模型都必须继承这个类
def forward(self,input):
# 把输入的加个1再返回出去
output = input+1
return output
# 初始化这个类
module = Module()
x = torch.tensor(1.0)
y = module(x)
print(y)下面一一往框架里填充内容,让我们的神经网络丰富起来~
卷积层的使用
如何去理解卷积层
学过数字图像处理应该就很好理解这个概念,就是拿一个模板去遍历图像里的栅格,得到一个处理过的新图像。
更为详细的理解就不赘述了,在网上有很多很好的视频教程。
我们在官方文档的介绍里看到有很多种卷积层结构,1d即为一维卷积核,2d即为二维卷积核,我们以最常用的二维卷积核为代码实例

如何去使用卷积层
结合上文里学到的知识点做一次代码实操记录
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
# 引入数据集
dataset = torchvision.datasets.CIFAR10(root = './CIFAR10',train = False,transform = torchvision.transforms.ToTensor() ,download=False)
# 每次中数据集中取64张照片
dataloader = DataLoader(dataset=dataset ,batch_size = 64)
class Module(nn.Module):
def __init__(self):
super().__init__()
# 先在__init__定义好conv1之后才可以在后续中调用
# Conv2d参数含义往下看
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size = 3, stride=1, padding=1)
def forward(self,x):
x = self.conv1(x)
return x
module = Module()
writer = SummaryWriter('CIFAR10')
for data in dataloader:
imgs,targets = data
input = imgs
output = module(imgs)
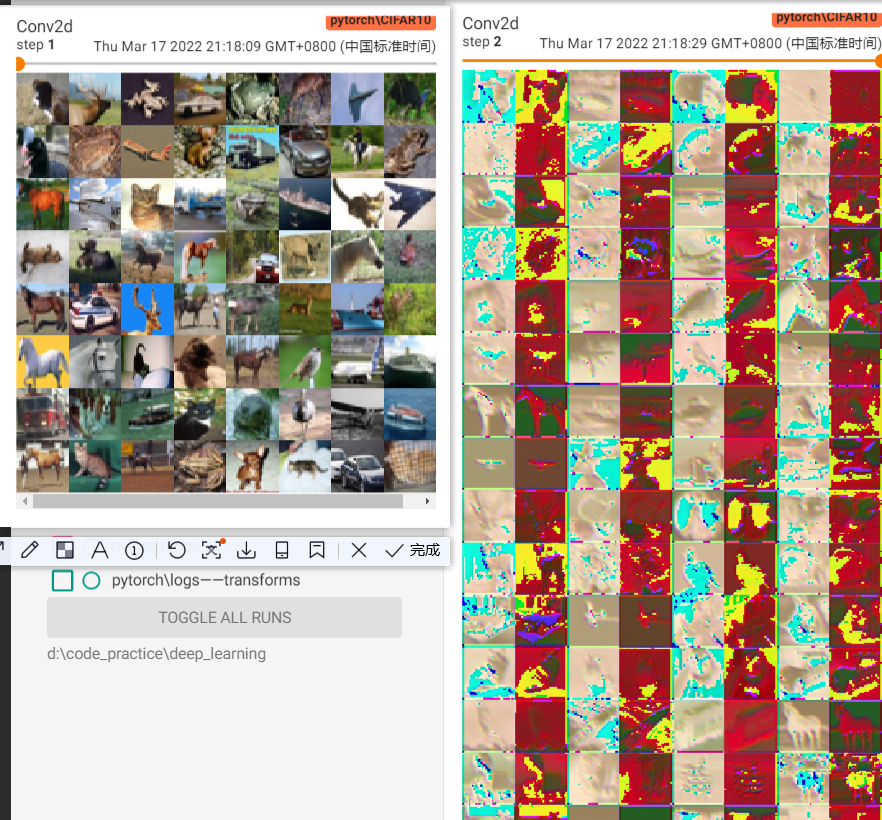
# torch.size([64,3,32,32])
writer.add_images("Conv2d",input,1)
# torch.size([64,6,30,30]) -> [-1,3,30,30]
# add_images不支持加载6通道的Tensor,所以需要做一下reshape,reshape之后变成了[128,3,30,30]
# -1的意思是 这个位置的大小自动计算出
output = torch.reshape(output,(-1,3,32,32))
writer.add_images("Conv2d",output,2)
step += 1
writer.close()Conv2d具体参数含义:
- in_channels:输入通道数,一般照片都是3,在遥感影像里就要多注意
- out_channels:卷积后的通道数
- kernel_size:卷积核的长*宽,kernel_size = 3 即 3*3的卷积核
- stride:卷积核每次移动的格数,默认都是1
- padding:边缘填充格数,这决定了输入的图像尺寸大小,这个参数由卷积核的大小和输入图像尺寸决定,画图一看就很好理解,不要去背公式!
result:
这里明显可以看出,输入的图像是64张,输入变成了128张
卷积之后的图片也变得面目全非~这就算是一次特征变换吧
池化层
如何去理解池化层
池化层一般来说就是降采样。有很多种池化方式,最常见的是最大池化
- https://www.bilibili.com/video/BV1hE411t7RN?p=19
- https://pytorch.org/docs/stable/nn.html#pooling-layers
以最大池化为例:将输入的图像划分为若干个矩形区域,对每个子区域输出最大值,如下图所示
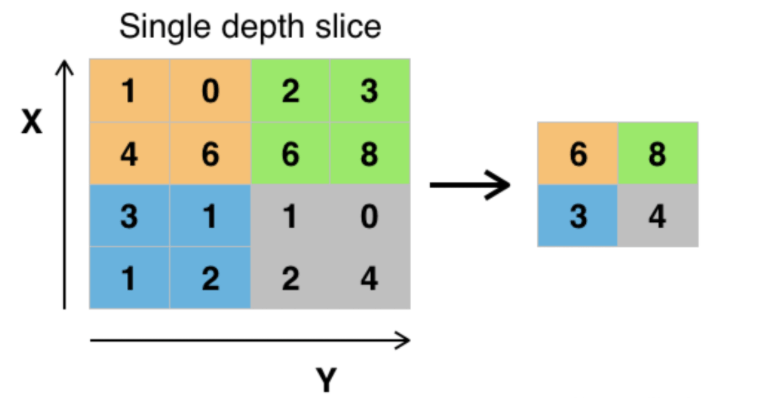
从上面的例子可以看出,池化层的引入明显就是一种对于数据的压缩,为什么要引入池化层呢
- 降维、去除冗余信息、对特征进行压缩、简化网络复杂度
- 在一定程度上也控制了过拟合
如何去使用池化层
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root = './CIFAR10',train = False,transform = torchvision.transforms.ToTensor() ,download=False)
dataloader = DataLoader(dataset=dataset ,batch_size = 64)
class Module(nn.Module):
def __init__(self):
super().__init__()
# 在__init__定义好MaxPool2d
# 参数见下
self.maxP2d = MaxPool2d(kernel_size = 2, stride= 2, padding=1)
def forward(self,x):
x = self.maxP2d(x)
return x
module = Module()
writer = SummaryWriter('CIFAR10')
for data in dataloader:
imgs,targets = data
input = imgs
output = module(imgs)
# torch.size([64,3,32,32])
writer.add_images("maxpool",input,1)
# torch.size([64,3,16,16])
writer.add_images("maxpool",output,2)
writer.close()MaxPool2d具体参数含义:基本和卷积层很像
- kernel_size:层化核的长*宽,kernel_size =2 即 3*3的层化核
- stride:层化核每次移动的格数
- padding:边缘填充格数,这决定了输入的图像尺寸大小,这个参数由卷积核的大小和输入图像尺寸决定,画图一看就很好理解,不要去背公式!
图像池化之后很明显的变模糊了,因为像素格数发生了变化 [3,32,32] –> [3,16,16]

非线性激活
什么是非线性激活
就是引入激活函数,使得神经网络有拟合非线性函数的能力,这样就可以任意逼近任何非线性函数,从而应用到众多的非线性模型中。
常见的激活函数
先列着,以后深刻理解了各自的应用场景之后再来补充
Sigmoid激活函数
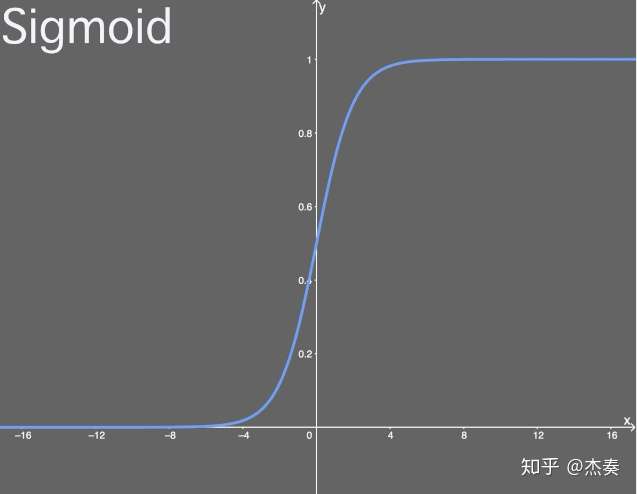
函数式:
导数式:
值域:(0,1)
ReLU激活函数
ReLU又叫“修正线性单元”,或者“线性整流函数”。
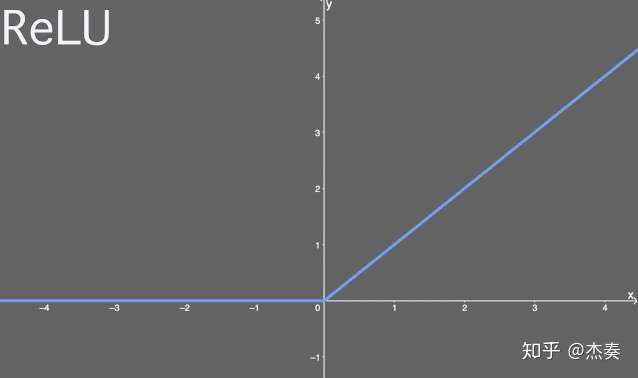
函数式:
导数式:
值域:[0,+∞)
激活函数的使用
就不重复写一大堆了
class Module(nn.Module):
def __init__(self):
super().__init__()
# 先声明好
self.ReLU = ReLU(False)
self.Sigmoid = Sigmoid()
# 再调用
def forward(self,x):
x = self.Sigmoid(x)
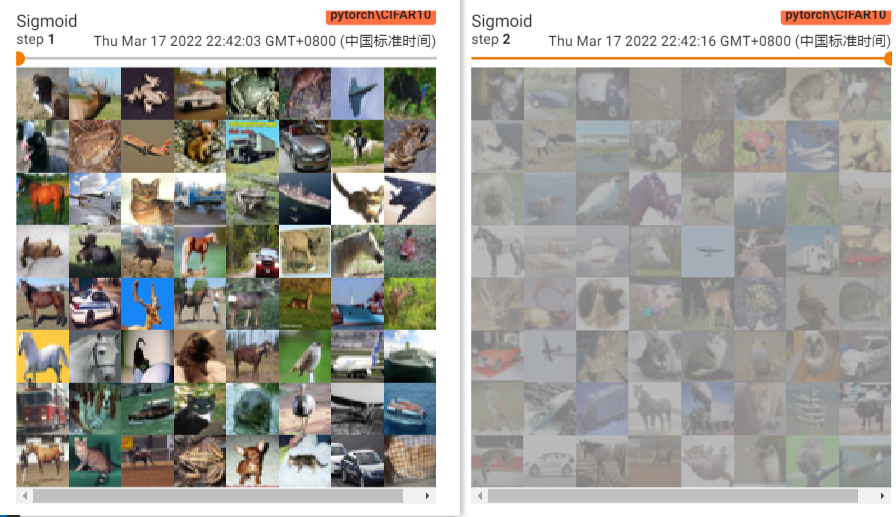
return x这里我们用的是Sigmoid,看值域压缩到(0,1),看一下对比结果
可以发现压缩之后就仿佛蒙上了一层蒙版,雾里看图的感觉
线性层
线性层又称为全连接层,其每个神经元与上一个层所有神经元相连,实现对前一层的线性组合或线性变换
我对线程层的理解就是最后的分类,不知道对不对
让我们简单看个例子
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root = './CIFAR10',train = False,transform = torchvision.transforms.ToTensor() ,download=False)
dataloader = DataLoader(dataset=dataset ,batch_size = 64,drop_last =True)
class Module(nn.Module):
def __init__(self):
super().__init__()
# 定义线性层
self.Linear = Linear(196608,10)
def forward(self,x):
x = self.Linear(x)
return x
module = Module()
for data in dataloader:
imgs,targets = data
# torch.size([64,3,32,32])
input = imgs
print(input.shape)
# torch.size([196608])
output = torch.flatten(imgs)
print(output.shape)
# torch.size([10])
output1 = module(output)
print(output1.shape)
writer.close()Linear(196608,10) 第一个参数196608是由输入图像的特征所得到的
即 64,3,32,32 四个数相乘 = 196608,
为什么要 在module(output)之前 加一个flatten呢?就是对高维张量tensor做一个压缩,这样才能满足Linear的参数格式
Linear的用法很直接,最终打印的tensor.shape也和我们预想的一样
Sequential
Sequential就是一种简化表达
如果你的模型很复杂,有很多中间层,没有Sequential,写起来可能就是这样
class Module(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels = 3,out_channels= 32,kernel_size= 5,padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(in_channels = 32,out_channels= 32,kernel_size= 5,padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(in_channels = 32,out_channels= 64,kernel_size= 5,padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.Linear1 = Linear(1024,64)
self.Linear2 = Linear(64,10)有了Sequential,写起来就是这样:
class Module(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(in_channels = 3,out_channels= 32,kernel_size= 5,padding=2),
MaxPool2d(2),
Conv2d(in_channels = 32,out_channels= 32,kernel_size= 5,padding=2),
MaxPool2d(2),
Conv2d(in_channels = 32,out_channels= 64,kernel_size= 5,padding=2) ,
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)代码的简洁明了很重要
损失函数 & 反向传播
概念介绍
神经网络的训练过程一般来说就是 在已经x和y(又称标签)的训练集中,输入一个值(x),通过一连串的网络结构(前向反馈)之后得到 预测的一个值(y’),计算y‘和y的差距(损失函数),将这个差距反馈给网络(反向传播),以此来更新网络中的参数,以上的过程被称为一个epoch;然后我们再传入一次参数,一直往复,直至我们的损失函数小到让我们接受。
损失函数就是用一个函数来衡量我们预测的值和实际的值的差距是多少
不同的损失函数,有着不同的计算方式,适用于不同的场景,常见的有最小二乘、交叉熵、平均绝对值误差

官方文档给出了很多损失函数,以后再去慢慢探究其中的差异
反向传播是现在众多深度学习训练方法的基础,通过计算神经网络中损失函数对各参数的梯度,配合优化方法更新参数,从而降低损失函数。
介绍一下主要的优化器:
SGD,随机梯度下降
SGDM,SGD with momentum,加入动量机制的SGD
Adagrad,自适应梯度下降。利用迭代次数和累计梯度,对学习率进行自动衰减
学习率除以前t-1迭代的梯度平方和,没有考虑迭代衰减
RMSProp,在Adagrad的基础上加入了对于迭代衰减的考虑,学习率除以前t-1迭代的梯度的加权平方和。与当前迭代越近的梯度,对当前的影响应该越大。
Adam,SGDM和RMSProp的结合,基本解决了梯度下降的一系列问题,比如随机小样本、自适应学习率、容易卡在梯度较小点等问题。
(具体比较在之后补充)
代码实操
先以交叉熵和SGD作为代码实例
# 定义要用什么损失函数
loss = nn.CrossEntropyLoss()
# 定义要用什么反向传播优化器
optimizer = optim.SGD(params = model.parameters(), lr=0.01, momentum=0.9)
# 数据训练一轮是不够的,需要多轮训练,即多个epoch
for epoch in range(10):
for data in dataloader:
imgs,targets = data
outputs = module(imgs)
result_loss = loss(outputs,targets)
# 每次优化前都对模型中的参数梯度做清零
optim.zero_grad()
# 求出每个节点的梯度
result_loss.backward()
# 对模型参数进行调优
optim.step()optim.SGD具体参数介绍:
- params:优化器要对哪个模型的参数做优化,这里填的是model.parameters()
- lr:leanring rate,学习率,学习率的设置影响了模型训练的速率和好坏,需要根据实际情况做多次测试进行调整
- momentum:动量大小,
pytorch里的SGD方法实际上就涵盖了SGD和SGDM,区别就在于是否设置momentum
设置了momentum,就是SGDM
不设置momentum,就是SGD
模型的使用及修改
官方文档里内置了很多有名的深度学习模型,当我们想直接使用的时候需用在model下调用即可
- 计算机视觉的模型:https://pytorch.org/vision/stable/models.html
- NLP的模型:https://pytorch.org/audio/stable/models.html#conformer
以vgg16模型为例,如何使用呢

以上简单两行代码就可以了,其中pretrained表示是否下载训练好的模型
pretrained (bool): If True, returns a model pre-trained on ImageNet
当我们打印这个模型的时候会发现,最后的输出是1000,即这个模型可以分类出1000个类别
当我们将这个模型用在自己的数据集,肯定要做一些修改,
比如我们的数据集类别只有10个类,那如何修改呢
import torchvision
vgg16_true = torchvision.models.vgg16(pretrained = True)
vgg16_false = torchvision.models.vgg16(pretrained = False)
# 在模型最下面添加一个线性层
vgg16_true.classifier.add_module("add_linear",nn.Linear(1000,10))
# 把模型最下面的一个线性层做修改
vgg16_false.classifier[6] = nn.Linear(4096,10)网络模型的保存与读取
模型的保存和读取是一起的,各有两种方式
vgg16_false = torchvision.models.vgg16(pretrained = False)
# 保存方式1,可以保存下来模型的结构+模型里的参数
torch.save(obj = vgg16_false, f = "vgg16_method1.pth")
# 加载方式1
model = torch.load("vgg16_method1.pth")
print(model)vgg16_true = torchvision.models.vgg16(pretrained = True)
# 保存方式2,只保存 模型的参数(推荐)
torch.save(vgg16_true.state_dict,"vgg16_method2.pth")
# 加载方式2
vgg16_true.load_state_dict(torch.load("vgg16_method2.pth"))
如何使用GPU训练
GPU是深度学习必不可少的一块内容,可以提高训练速度。
使用GPU训练,其他的地方都不用改动
只需要改动三块内容,分别是网络模型、数据和损失函数
方式一
# 网络模型
model = Module()
if torch.cuda.is_available:
model = model.cuda()# 数据
if torch.cuda.is_available:
imgs = imgs.cuda()
targets = targets.cuda()# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available:
loss_fn = loss_fn.cuda()方式二
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 网络模型
model.todevice(device)
# 数据
imgs.todevice(device)
targets.todevice(device)
# 损失函数
loss_fn.todevice(device)!nvidia -smi
这个命令查看本机的GPU配置和使用情况到这里,pytorch主要模块的介绍就结束了。
把这些组装起来,就是一个完整简单的深度学习框架。
下篇笔记中,做一个完整的实例介绍。