书接上回,继续做笔记
![]()
神经网络的搭建
可以把以下代码当成个模板,有什么内容在里面填充即可
以下只涉及了前向反馈,是最简单的模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import torch
from torch import nn
class Module(nn.Module):
def __init__(self):
super().__init__()
def forward(self,input):
output = input+1
return output
module = Module()
x = torch.tensor(1.0)
y = module(x)
print(y)
|
下面一一往框架里填充内容,让我们的神经网络丰富起来~
卷积层的使用
如何去理解卷积层
学过数字图像处理应该就很好理解这个概念,就是拿一个模板去遍历图像里的栅格,得到一个处理过的新图像。
更为详细的理解就不赘述了,在网上有很多很好的视频教程。
我们在官方文档的介绍里看到有很多种卷积层结构,1d即为一维卷积核,2d即为二维卷积核,我们以最常用的二维卷积核为代码实例
![]()
如何去使用卷积层
结合上文里学到的知识点做一次代码实操记录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root = './CIFAR10',train = False,transform = torchvision.transforms.ToTensor() ,download=False)
dataloader = DataLoader(dataset=dataset ,batch_size = 64)
class Module(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size = 3, stride=1, padding=1)
def forward(self,x):
x = self.conv1(x)
return x
module = Module()
writer = SummaryWriter('CIFAR10')
for data in dataloader:
imgs,targets = data
input = imgs
output = module(imgs)
writer.add_images("Conv2d",input,1)
output = torch.reshape(output,(-1,3,32,32))
writer.add_images("Conv2d",output,2)
step += 1
writer.close()
|
Conv2d具体参数含义:
- in_channels:输入通道数,一般照片都是3,在遥感影像里就要多注意
- out_channels:卷积后的通道数
- kernel_size:卷积核的长*宽,kernel_size = 3 即 3*3的卷积核
- stride:卷积核每次移动的格数,默认都是1
- padding:边缘填充格数,这决定了输入的图像尺寸大小,这个参数由卷积核的大小和输入图像尺寸决定,画图一看就很好理解,不要去背公式!
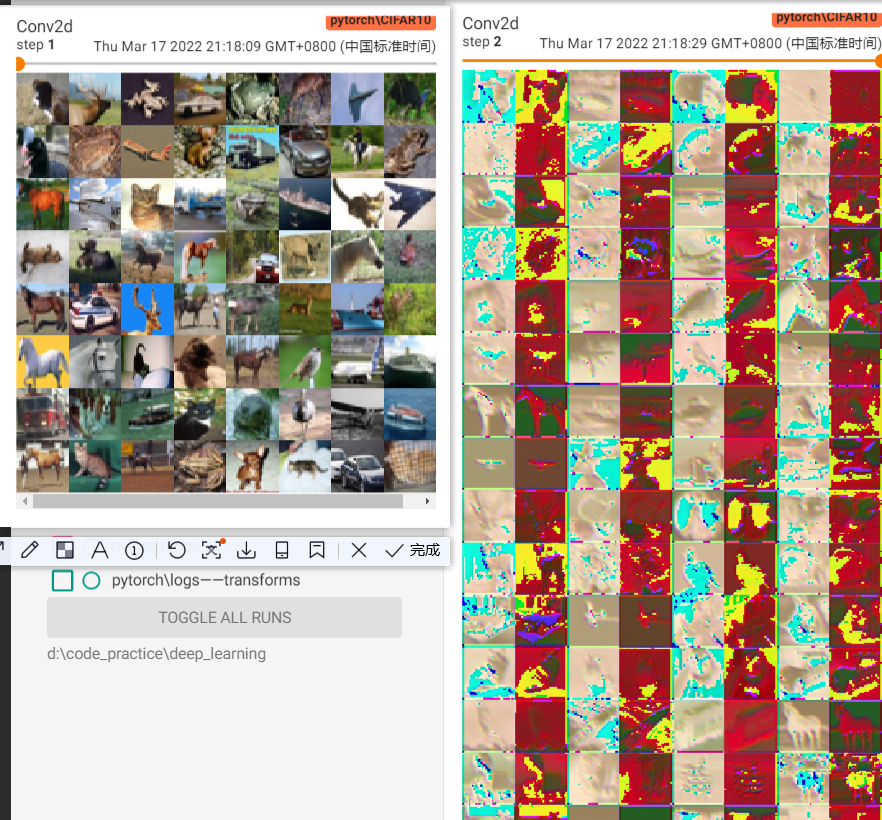
result:
这里明显可以看出,输入的图像是64张,输入变成了128张
卷积之后的图片也变得面目全非~这就算是一次特征变换吧
![]()
池化层
如何去理解池化层
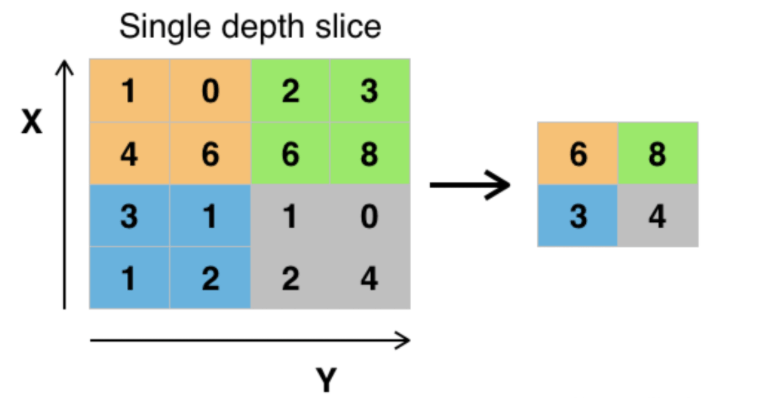
池化层一般来说就是降采样。有很多种池化方式,最常见的是最大池化
以最大池化为例:将输入的图像划分为若干个矩形区域,对每个子区域输出最大值,如下图所示
![]()
从上面的例子可以看出,池化层的引入明显就是一种对于数据的压缩,为什么要引入池化层呢
- 降维、去除冗余信息、对特征进行压缩、简化网络复杂度
- 在一定程度上也控制了过拟合
如何去使用池化层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root = './CIFAR10',train = False,transform = torchvision.transforms.ToTensor() ,download=False)
dataloader = DataLoader(dataset=dataset ,batch_size = 64)
class Module(nn.Module):
def __init__(self):
super().__init__()
self.maxP2d = MaxPool2d(kernel_size = 2, stride= 2, padding=1)
def forward(self,x):
x = self.maxP2d(x)
return x
module = Module()
writer = SummaryWriter('CIFAR10')
for data in dataloader:
imgs,targets = data
input = imgs
output = module(imgs)
writer.add_images("maxpool",input,1)
writer.add_images("maxpool",output,2)
writer.close()
|
MaxPool2d具体参数含义:基本和卷积层很像
- kernel_size:层化核的长*宽,kernel_size =2 即 3*3的层化核
- stride:层化核每次移动的格数
- padding:边缘填充格数,这决定了输入的图像尺寸大小,这个参数由卷积核的大小和输入图像尺寸决定,画图一看就很好理解,不要去背公式!
图像池化之后很明显的变模糊了,因为像素格数发生了变化 [3,32,32] –> [3,16,16]
![]()
非线性激活
什么是非线性激活
就是引入激活函数,使得神经网络有拟合非线性函数的能力,这样就可以任意逼近任何非线性函数,从而应用到众多的非线性模型中。
常见的激活函数
先列着,以后深刻理解了各自的应用场景之后再来补充
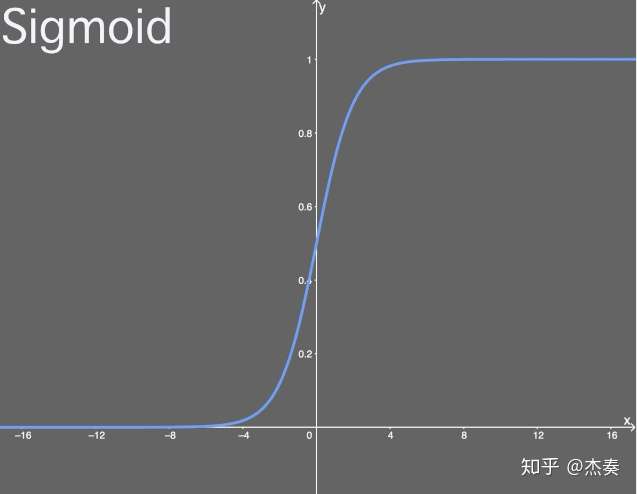
Sigmoid激活函数
![]()
函数式: ![]()
导数式: ![]()
值域:(0,1)
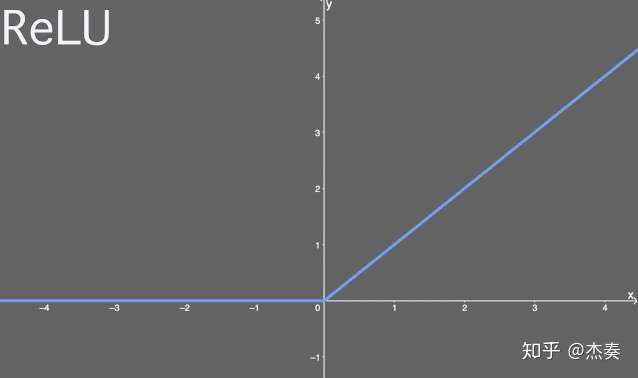
ReLU激活函数
ReLU又叫“修正线性单元”,或者“线性整流函数”。
![]()
函数式: ![[公式]]()
导数式: ![[公式]]()
值域:[0,+∞)
激活函数的使用
就不重复写一大堆了
1
2
3
4
5
6
7
8
9
10
| class Module(nn.Module):
def __init__(self):
super().__init__()
self.ReLU = ReLU(False)
self.Sigmoid = Sigmoid()
def forward(self,x):
x = self.Sigmoid(x)
return x
|
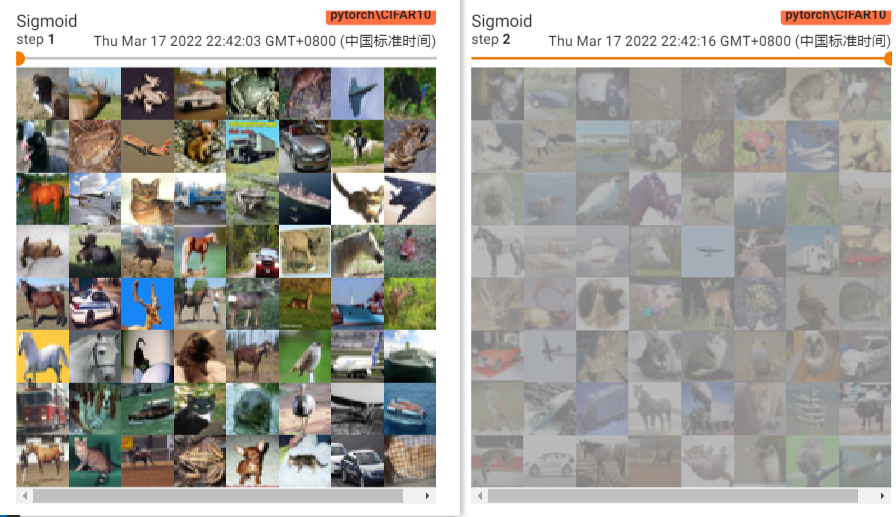
这里我们用的是Sigmoid,看值域压缩到(0,1),看一下对比结果
可以发现压缩之后就仿佛蒙上了一层蒙版,雾里看图的感觉
![image-20220317230130950]()
线性层
线性层又称为全连接层,其每个神经元与上一个层所有神经元相连,实现对前一层的线性组合或线性变换
我对线程层的理解就是最后的分类,不知道对不对
让我们简单看个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root = './CIFAR10',train = False,transform = torchvision.transforms.ToTensor() ,download=False)
dataloader = DataLoader(dataset=dataset ,batch_size = 64,drop_last =True)
class Module(nn.Module):
def __init__(self):
super().__init__()
self.Linear = Linear(196608,10)
def forward(self,x):
x = self.Linear(x)
return x
module = Module()
for data in dataloader:
imgs,targets = data
input = imgs
print(input.shape)
output = torch.flatten(imgs)
print(output.shape)
output1 = module(output)
print(output1.shape)
writer.close()
|
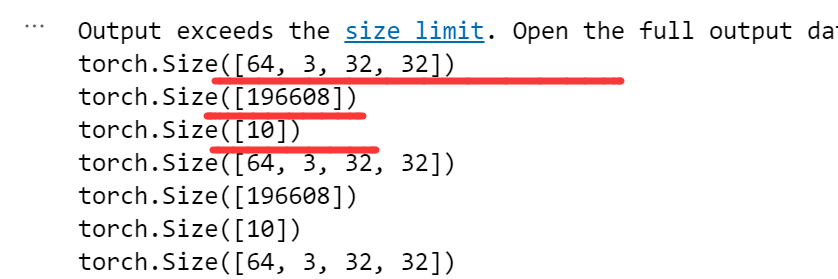
Linear(196608,10) 第一个参数196608是由输入图像的特征所得到的
即 64,3,32,32 四个数相乘 = 196608,
为什么要 在module(output)之前 加一个flatten呢?就是对高维张量tensor做一个压缩,这样才能满足Linear的参数格式
Linear的用法很直接,最终打印的tensor.shape也和我们预想的一样
![]()
Sequential
Sequential就是一种简化表达
如果你的模型很复杂,有很多中间层,没有Sequential,写起来可能就是这样
1
2
3
4
5
6
7
8
9
10
11
12
| class Module(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels = 3,out_channels= 32,kernel_size= 5,padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(in_channels = 32,out_channels= 32,kernel_size= 5,padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(in_channels = 32,out_channels= 64,kernel_size= 5,padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.Linear1 = Linear(1024,64)
self.Linear2 = Linear(64,10)
|
有了Sequential,写起来就是这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| class Module(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(in_channels = 3,out_channels= 32,kernel_size= 5,padding=2),
MaxPool2d(2),
Conv2d(in_channels = 32,out_channels= 32,kernel_size= 5,padding=2),
MaxPool2d(2),
Conv2d(in_channels = 32,out_channels= 64,kernel_size= 5,padding=2) ,
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
|
代码的简洁明了很重要
损失函数 & 反向传播
概念介绍
神经网络的训练过程一般来说就是 在已经x和y(又称标签)的训练集中,输入一个值(x),通过一连串的网络结构(前向反馈)之后得到 预测的一个值(y’),计算y‘和y的差距(损失函数),将这个差距反馈给网络(反向传播),以此来更新网络中的参数,以上的过程被称为一个epoch;然后我们再传入一次参数,一直往复,直至我们的损失函数小到让我们接受。
损失函数就是用一个函数来衡量我们预测的值和实际的值的差距是多少
不同的损失函数,有着不同的计算方式,适用于不同的场景,常见的有最小二乘、交叉熵、平均绝对值误差
![image-20220318110120972]()
官方文档给出了很多损失函数,以后再去慢慢探究其中的差异
反向传播是现在众多深度学习训练方法的基础,通过计算神经网络中损失函数对各参数的梯度,配合优化方法更新参数,从而降低损失函数。
介绍一下主要的优化器:
SGD,随机梯度下降
SGDM,SGD with momentum,加入动量机制的SGD
Adagrad,自适应梯度下降。利用迭代次数和累计梯度,对学习率进行自动衰减
学习率除以前t-1迭代的梯度平方和,没有考虑迭代衰减
RMSProp,在Adagrad的基础上加入了对于迭代衰减的考虑,学习率除以前t-1迭代的梯度的加权平方和。与当前迭代越近的梯度,对当前的影响应该越大。
Adam,SGDM和RMSProp的结合,基本解决了梯度下降的一系列问题,比如随机小样本、自适应学习率、容易卡在梯度较小点等问题。
(具体比较在之后补充)
代码实操
先以交叉熵和SGD作为代码实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
loss = nn.CrossEntropyLoss()
optimizer = optim.SGD(params = model.parameters(), lr=0.01, momentum=0.9)
for epoch in range(10):
for data in dataloader:
imgs,targets = data
outputs = module(imgs)
result_loss = loss(outputs,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
|
optim.SGD具体参数介绍:
- params:优化器要对哪个模型的参数做优化,这里填的是model.parameters()
- lr:leanring rate,学习率,学习率的设置影响了模型训练的速率和好坏,需要根据实际情况做多次测试进行调整
- momentum:动量大小,
pytorch里的SGD方法实际上就涵盖了SGD和SGDM,区别就在于是否设置momentum
设置了momentum,就是SGDM
不设置momentum,就是SGD
模型的使用及修改
官方文档里内置了很多有名的深度学习模型,当我们想直接使用的时候需用在model下调用即可
以vgg16模型为例,如何使用呢
![]()
以上简单两行代码就可以了,其中pretrained表示是否下载训练好的模型
pretrained (bool): If True, returns a model pre-trained on ImageNet
当我们打印这个模型的时候会发现,最后的输出是1000,即这个模型可以分类出1000个类别
当我们将这个模型用在自己的数据集,肯定要做一些修改,
比如我们的数据集类别只有10个类,那如何修改呢
1
2
3
4
5
6
7
8
9
10
| import torchvision
vgg16_true = torchvision.models.vgg16(pretrained = True)
vgg16_false = torchvision.models.vgg16(pretrained = False)
vgg16_true.classifier.add_module("add_linear",nn.Linear(1000,10))
vgg16_false.classifier[6] = nn.Linear(4096,10)
|
网络模型的保存与读取
模型的保存和读取是一起的,各有两种方式
1
2
3
4
5
6
7
| vgg16_false = torchvision.models.vgg16(pretrained = False)
torch.save(obj = vgg16_false, f = "vgg16_method1.pth")
model = torch.load("vgg16_method1.pth")
print(model)
|
1
2
3
4
5
6
7
| vgg16_true = torchvision.models.vgg16(pretrained = True)
torch.save(vgg16_true.state_dict,"vgg16_method2.pth")
vgg16_true.load_state_dict(torch.load("vgg16_method2.pth"))
|
如何使用GPU训练
GPU是深度学习必不可少的一块内容,可以提高训练速度。
使用GPU训练,其他的地方都不用改动
只需要改动三块内容,分别是网络模型、数据和损失函数
方式一
1
2
3
4
|
model = Module()
if torch.cuda.is_available:
model = model.cuda()
|
1
2
3
4
|
if torch.cuda.is_available:
imgs = imgs.cuda()
targets = targets.cuda()
|
1
2
3
4
|
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available:
loss_fn = loss_fn.cuda()
|
方式二
1
2
3
4
5
6
7
8
9
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.todevice(device)
imgs.todevice(device)
targets.todevice(device)
loss_fn.todevice(device)
|
1
2
| !nvidia -smi
这个命令查看本机的GPU配置和使用情况
|
到这里,pytorch主要模块的介绍就结束了。
把这些组装起来,就是一个完整简单的深度学习框架。
下篇笔记中,做一个完整的实例介绍。
参考文章